Commit Policies
Git is a complicated beast. The Git index, if you’re coming from other VCS’s, is a new concept. Yesterday I described how I use the Git index in my workflow:
![]()
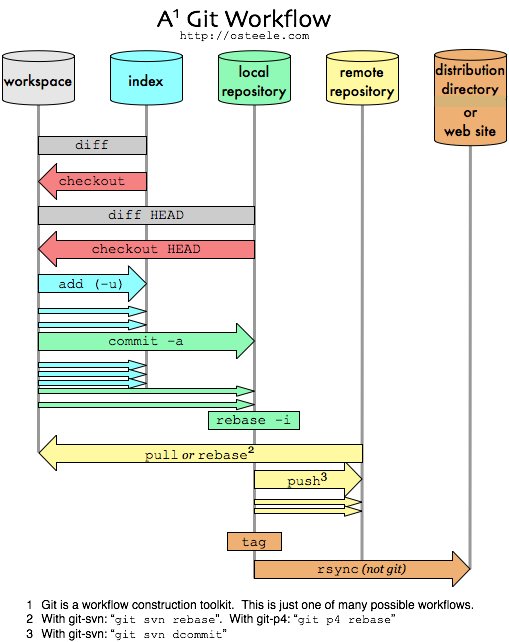
These pictures illustrate the multiple locations, or “data stores”, that host a copy of the source tree. These stores are: the working directory, local and remote repositories, and the index. In order to show more of the whole development process, the second picture also includes a “distribution directory”, for code that is being distributed outside of Git. (The distribution directory could be the deployment directory of a web site, or a compiled artifact, such as a binary, that is placed in firmware or on a DVD.)
Salmon Run Development
The x axis in these pictures is actually meaningful. In fact, it has several meanings. Towards the left is personal (only I can see my working directory); towards the right is public (the remote repository is visible to other developers; the distribution directory to users as well). Towards the left is closer to closer to development, towards the right is closer to production. Towards the left is easier to change; towards the right is more stable1.
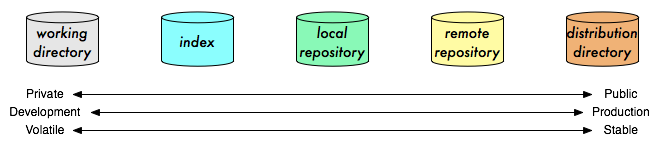
Two of the most important properties of a project are its design flexibility (the ease with which developers can change it), and its stability. Flexibility is necessary in order to maintain development velocity, to accommodate changing requirements, and to explore design spaces. Stability is important in order to maintain quality (by allowing settling time for bugs, and by reducing their injection rate), and to synchronize with separately developed artifacts (test suites, test plans, and documentation, if they’re not in the repository; and books, forum and blog postings, and user knowledge). Unfortunately, these properties conflict.
Putting each of these constraints at the opposite end of the chain of data stores allows you to compromise each individual data store less. You don’t need to maintain as stable a workspace, but the remote repository needn’t be yanked around as much.

I picture the process of moving edits from my working directory to a distribution as a multi-stage transmission, where each step to the right steps down in speed (development velocity) but up in torque (quality). Making the chain longer means there’s more of an impedance match between any two successive stores. This is why DVCS is better than VCS; and it’s why I like to use the index as a staging area2.
I also picture the process of moving edits to a distribution as a salmon run3. To make it from the index up to a distribution, a change has to swim up a series of falls. Each level of the stream is a data store; it has to leap the lowest fall to make it into the index, and another to make it into the local repository. Only a few changes are strong enough to make it all the way. [Although, unlike salmon, changes can team up to make a stronger fish. Or maybe I’m not talking about salmon, but salmon DNA. I’ll drop the metaphor in a moment :-)]
What makes the falls steep – what makes it more difficult for a change to get further towards distribution – isn’t (in this age of fast networks, reliable DVCS, and automated deployment recipes) a technical limitation; it’s a matter of convention. In this case, it’s a matter of conventions that are constructed to maintain the quality of releases, by maintaining invariants on the data stores that feed into them. These conventions are commit policies.
Commit Policies
The most helpful paper I’ve read on source control is “High-level Best Practices in Software Configuration Management”, by Laura Wingerd and Christopher Seiwald of Perforce Software. Its most helpful recommendation is “Give each codeline a policy”. (The runners up are “branch on a policy change”, and “don’t branch unless necessary”.)
Git’s data stores are in many ways like anonymous, built-in branches, with a built-in set of commands that operate on them4. Like branches, I find it helpful to give each data store its own policy. Each policy is more rigorous than the policy to its left. These policies tell me how far upstream a change can swim.
Here’s an example of the policies I use in my personal projects, or for the non-shared part (the workspace, index, and local repository) of a collaborative project. “Revision Frequency” is how often I typically make changes to each data store, when I’m developing it full-time.
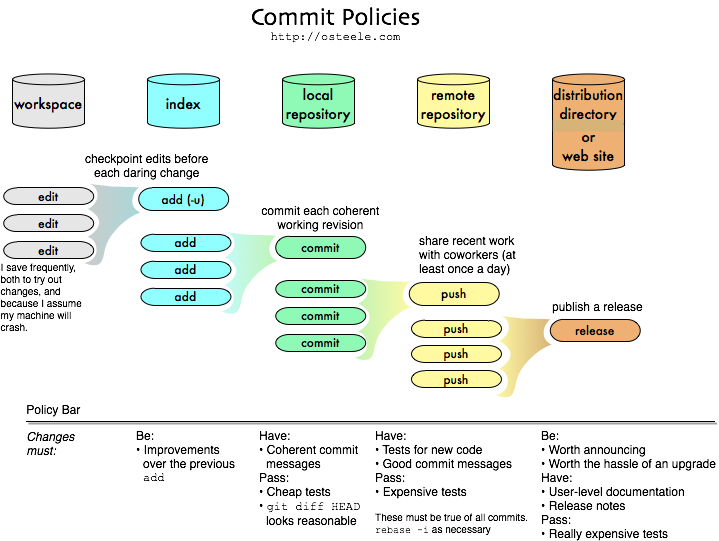
Policies implement the intent of the salmon run. By placing un-restrictive policies to the left, I can checkpoint my work frequently. By placing restrictive policies on the right, I can maintain the stability of releases. And by incrementing the restrictiveness of these policies in small steps, I reduce the backlog of code that is “trapped” towards the left. Compare this to a centralized VCS, in which (since there’s no local repository), developers may keep changes out of VCS for hours or days (since the alternative is making a central branch, which is expensive to create and expensive to tear down). Or compare to a DVCS system without an index, where the overhead of either making and tearing down branches, or of pruning temporary commits, can discourage a developer from making a checkpoint every minute or two. (At least they discourage me, even though these operations are far less expensive than with centralized VCS.)
And no, I’m not saying to do this instead of branching. I find this system useful as an always-on, lightweight alternative to branching, and then add in branching when the lifting gets heaver. This process, without branches, is as much mechanism as I usually want for small, personal projects such as these. For a collaborative project, I often synch to a feature branch of the main repository. For an experiment that takes more than half a day, and that I therefore want to be able to set aside, I make a local branch. And for a shared collaborative experiment, or a feature that calls on only part of the development team, I do both.
More on branches tomorrow.
-
The reasons for these differences are partly convention, but mostly technical. I can easily make and revert changes in my workspace with my editor (or another tool). Changes to the index and the local repository require some extra work with some command line intervention but can still be rolled back (via
get rebase -iandgit reset) without a trace. Changes to the remote repository are carved in stone (I can only revert them withgit revert, which reverses the reverted change but leaves both it and its reversion in the permanent record). Changes to the distribution require a new version number, an announcement, and, depending on the circumstances, a recall notice and egg on my face. ↩ -
But why not use branches? Yeah, I’ll get to branches. But the answer is mostly just personal preference. ↩
-
Since you’re such a careful reader that you even bother to read footnotes, I’ll let you in on a secret. I like to think about abstract stuff, but I’m not much good with abstractions. Instead, I try to keep my concept library well-stocked with metaphors. Then the hard parts become easy again. ↩
-
For example,
git difftells me what’s different between my working directory and the index, without my having to build up, tear down, or remember any branch names. The working directory and the index are self-cleaning (they don’t collect commits that I have to squash later); this has advantages and disadvantages, but it works for me and for the granularity with which I save to them. ↩