Test versus Type
A lightweight language such as Python or JavaScript fits a lot of program design into a small amount of source text. A heavyweight language such as C++ or Java uses more tokens to express the same design.
Many people (Guido van Rossum, Bruce Eckels, Steve Ferg) report that working in a lightweight language is about five times more productive than working in a heavyweight language. This matches my personal experience. Lutz Prechelt1 reproduces this difference within a research setting.
It’s easy to make up reasons why it’s easier to work with shorter sources. There’s less data entry, fewer places to make mistakes, and it’s easier to read the programs. A program in a heavyweight language has a lot of boilerplate that doesn’t add information about the program’s design or intent. Eliminating the boilerplate seems like a clear win.
But what about source text that does add information about the program – in particular, what about types? Removing type declarations from a program also makes it shorter, but it removes information that the compiler and runtime can use to verify the program. Doesn’t this make the program less reliable? Or, given a reliability goal, doesn’t it make it take longer to reach that goal?
From the anecdotes and studies above, it looks like this isn’t actually the case. I’d like to look at why.
Two Types of Types
An Explicitly-Typed Language (ETL) is one in which functions and variables must be declared with type declarations. (These type declarations are conventionally called manifest types.) Java and C++ are ETLs.
An Implicitly-Typed Language (ITL) is one in which type declarations are not necessary. Some ITLs, such as JavaScript 1.5 and Python, lack type declarations altogether. In other ITLs, such as Dylan, Haskell, JavaScript 2.0, and JScript.NET, type declarations are optional, and can be added at any point during program development.
An ITL isn’t necessarily a weakly typed language. (In a weakly typed language, type mismatches are never detected. C++ is weakly typed where it uses with static casts.) Python is an example of latent typing: types are always checked, just not at compile time.
Neither is an ITL necessarily a dynamically typed language. Haskell and ML are examples of statically typed languages where the type declarations are often optional, but the types are known at compile time. The compiler infers variable and function types from the source, just as a Java or C++ compiler infers the types of individual subexpressions.
(This discussion is condensed from the appendix to Steve Ferg’s excellent article comparing Python to Java.)
No Pain No Gain?
It’s common knowledge that it takes longer to get a program in an Explicitly-Typed Language to first clean compile, because it takes time to get the type declarations right. Initial program development consists of editing type declarations as well as non-declaration text (the expressions, control flow, and program structure), followed by a block of time to get the program to first clean compile. The white area below represents work on the non-declaration portion of a program; the gray stripes represent work on type declarations.
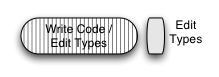
In order to show the division between time spent on type declarations and time spent on other program text more clearly, I’m going to slide the type declarations to the right:
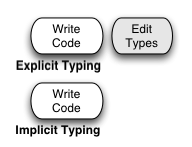
This picture appears to show that it takes more time to develop a program that contains type declarations. The received wisdom among ETL fans is that what you get for this extra time is error checking. ETL development takes longer, but gives you a more robust product. The equivalent ITL development effort (which isn’t shown here) would be even longer, because it would include debugging time to catch the problems that the compiler didn’t. In fact, some of these problems might not show up until the product is in the field.
Tests versus Types
Test-Driven Development (TDD) is a development methodology where the test cases are written first, and code is added to the program proper only as necessary to implement correct behavior for test cases.
TDD advocates have noted that if you write your test case first, you also get error checking. In fact, you get better error checking than you do with explicit types, because the tests are tailored to the code paths, the edge cases, and the specific problem domain. After all, the only kinds of errors that explicit typing catches are those of the kind where you used a string in integer context. Programmers who have used implicitly-typed languages can attest that these aren’t the kinds of errors that are hard to find. In fact, a lot of the work to make an ETL program compile is work that’s only necessary to get around how little to compiler knows about the runtime types.
The comparison of an ETL, where the extra work goes into typing explicit types, and an ITL with TDD, where the extra work goes into test cases, looks like this:
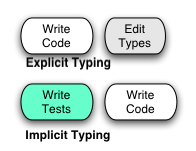
Let’s say you could start with a program without type declarations. Would you rather add type declarations, which catch a certain class of problems at compile time? Or would you rather add test cases, which in a strongly typed language catch this same class of problems at runtime, and catch problems that the type system can’t express as well?
But why not use TDD with an ETL?
Tests Plus Types
Here’s what happens when you use TDD with an ETL. You’re taking that first picture, and multiplying it by two: once for the test cases, and again for the program itself.
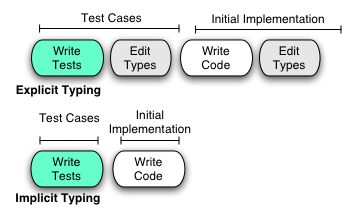
Robert Martin compares this TDD to dual-entry bookkeeping. Explicit types are another form a dual-entry bookkeeping. Using both explicit type declarations and test cases to validate is triple-entry bookkeeping. (And the time spent writing explicit types could have been spent on more test cases, or more of the program.)
But it’s actually worse than triple-entry bookkeeping, because an ETL requires that you use explicit type declarations in your test code too. Not only does the program itself cost more to write, but so do its test cases. It’s quadruple-entry bookkeeping: one of the three entries has two entries itself.
This is why even software written in an ETL is often tested with an ITL test harness. If you can afford to work in two languages, and if the test harness and the debugger are well-enough integrated that you can write the test cases first and use them for TDD, this works. (It brings the cost of using an ETL back down to triple-entry bookkeeping.) But there’s one more gotcha.
The Type Tax
The problem is that once type declarations are part of the source text, they’ve got to be maintained along with the rest of the code. The earlier the type declarations are added, the greater their contribution to the maintenance cost.
In a waterfall model of code construction, where all the code is written, brought to clean compile, and works the first time, this doesn’t matter. In incremental development, where compilable program is debugged or extended to handle additional features or test cases, the cost can be high.
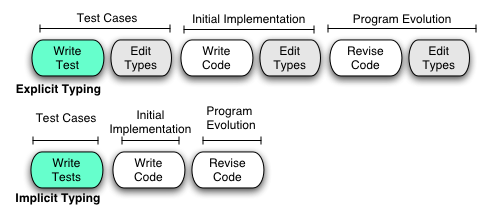
Types are similar to comments, test cases, and end-user documentation in this way, except that types are coupled more closely to each line of source text. Factor out a variable from an expression, and the method comment and end-user documentation can stay the same, but a new type declaration is required. This tight coupling makes the maintenance tax on types even higher than it is for other program annotations, and the tradeoff for when to start adding them, if at all, is different.
Since the cost/benefit ratio of type declarations can be different at different points in program maturity, one style would be to add them late in program development (for performance reasons, or for their documentation benefits to future maintainers). This style of development is possible in a language with optional type declarations, such as Dylan or Haskell. That’s what the first picture on this page shows. ETLs such as C++ and Java simply don’t allow this.
Updated 9/25/2003 to rename “write types” to “edit types”, and to add a picture showing type declarations interleaved on a finer grain.
-
An empirical comparison of C, C++, Java, Perl, Python, Rexx, and Tcl for a search/string-processing program, Lutz Prechelt. See especially figure 16. ↩