Serving Client-Side Applications
[Update 2006: “Model N” never caught on. A few months after I wrote this, Jesse James Garrett coined the term AJAX. This is what the architecture described in this post is known as today.]
In a traditional server-side web application, the server renders a series of views which are downloaded, as HTML, to the client. A client-side web application is an application that is deployed from a server and displays data from a server, but can render a series of views on the client.
I’ve been watching server-side developers try to figure out how to serve client-side web applications for a few years now. Different developers, that is — it doesn’t take years for any individual developer to figure it out. There’s often an initial stumble, which is caused by a mismatch between the obvious way to deploy a client-side web application, and the right way. The right way is simpler, but elusive.
Model 2
A server-side web application generates a sequence of HTML web pages. Each of these web pages represents an updated view of the data model, and sometimes an updated model. The diagram below illustrates this as a series of server requests. (In this example, each request is served from a JSP, but the pages could be coming from Perl, Python, PHP, or raw from the filesystem.) The JSP generates an HTML page, which is displayed in the browser. The generated page includes a link or a form which requests another URL from the server. The response to this subsequent request can come from either the same, or a different, JSP.
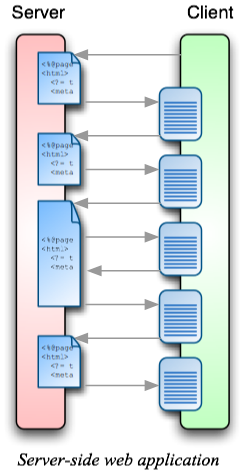
This is Server-Side MVC, or Model 2. I actually haven’t shown enough details in the diagram to distinguish this from Model 1 (the code that implements the Model, View, and Controller should be in separate files), but that’s because this is mostly irrelevant to this discussion. If this bothers you, pretend that there are additional files hiding in the server side of the diagram.
Introducing the Client-Side Application
A client-side web application is an application that renders views on the client, not the server. Client-side web applications are generally capable of a wide variety of user interactions without requiring a full update from the server — as opposed to a server-side application, where most user interactions replace the data on the client wholesale. Think GMail or Oddpost, say, or look at the Laszlo demos.
A client-side web application is different from a rich application in that the latter incorporates cinematic effects such as animation, dynamic layout, and media. Client-side and rich go well together for reasons I discuss here, but they aren’t the same. GMail is a client-side application, but it’s not a rich application. The Laszlo demos are both.
A client application might be simply HTML with a lot of embedded JavaScript1. Or it might be, as is the case with Laszlo, Flex, or SVG, an entirely different file type — possibly embedded within an HTML page that forms the initial download.
A server-side web application is delivered as a sequence of HTML pages which are rendered on the server. A client-side application is delivered as a single application file (or at least a single root file), that computes new views or view updates — does its rendering — without replacement, on the client.
For the sake of concreteness, let’s assume the client-side application is a Laszlo application. Not only does this allow me to plug my favorite RIA framework, but that’s where I have the clearest idea of what I’m talking about anyway.
The source code for a Laszlo application is a set of XML files and the assets (PNGs, JPEGs, XML data, and scriptless Flash files) that they include. The deployment set for a Laszlo application is a swf file (the Laszlo executable file), and the set of assets that the application requests once it has started. For simplicity, I’ll illustrate each Laszlo application as a single source file and a single deployment file:
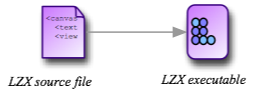
“Model 3”
From the server’s perspective, the most obvious difference between a server-side application and a client-side application is whether the server responds with an HTML file (generated by a JSP) or a Laszlo executable file (compiled from a Laszlo source file). You might think the simplest way to write a client-side application would therefore be to replace the JSPs on the server by Laszlo source files. This will cause the server to generate Laszlo executables instead of HTML pages — voila: a client-side application. I’ll call this Model 3, because it’s an incremental change from Model 2. It’s illustrated in the picture below.
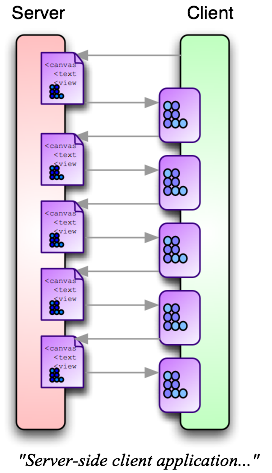
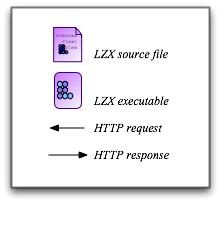
But something is wrong with this picture. Where did the back-end integration and middleware go? How does this work with Struts and CMS? Something is clearly missing. (In fact, the first question about Laszlo from any serious server-side developer is often “How do I use Laszlo with Struts?”)
“Model 4”
What Model 3 is missing is dynamic content generation. That’s what Struts, middleware, etc. are designed to deliver. In server-side programming, the JSP creates a new HTML in response to each request — that’s where the content generation comes in in Model 2. Where can we re-introduce this feature into Model 3?
Laszlo source code looks like HTML (well, XHTML): they’re both XML, and they can both embed JavaScript. It’s tempting to bring back the JSP, but use it to render a Laszlo source file instead of HTML. This source file is compiled on the server, and delivered to the client as an executable. I’ll call this Model 4.
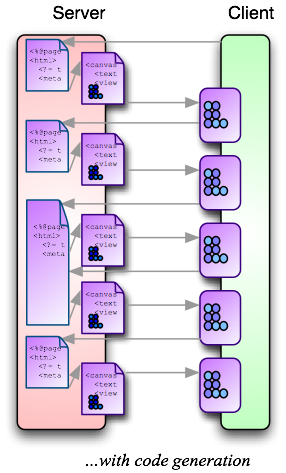
From the perspective of server-side programming, Model 4 looks natural, if a little bulky2. But Model 4 is wrong too.
To see the problem with Model 4, take off your implementor hat for a moment, and think about the user experience — in particular, about page refresh. Page refresh is one of the problems that client-side web programming is intended to solve.
In a server-side application, each user interaction3 results in a page refresh. This is why a server-side application is implemented as a series of HTML pages, instead of just one. This can be easier for the developer, because it unifies a lot of the architecture on the server. But it has a detrimental affect on the user: the user interface is laggy, can’t preview responses at interactive speeds, and requires a full-page refresh (losing a lot of the presentation context) whenever anything significant changes.
In other words, the benefit of a client-side application is that it’s a single-page application. The architecture above throws this advantage away. Model 4 only makes life harder for the application developer, without delivering any compensating benefit to the application user4.
Serving the Client
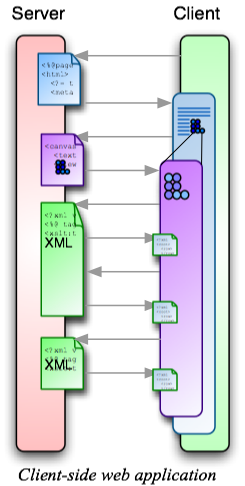
In a client-side web application, a single web page (or its application equivalent) is downloaded. This application can generate a sequence of views on the client. Sometimes the client application requests a new dataset — typically in XML, or a protocol (RPC, SOAP) that is serialized to XML — but this dataset is read into the client application; it doesn’t replace it.
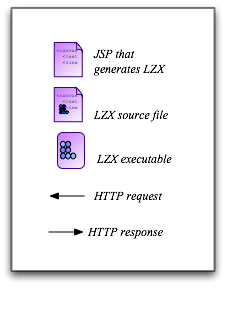
Here’s the architecture that delivers this. The files on the server include a JSP that generates an HTML embedding page, a Laszlo source file that generates a Laszlo executable that embeds within this page, and a set of JSPs that generate XML datasets. This is a particular implementation of a Service-Oriented Architecture, but in order to emphasize its continuity with Models 1-4, I’ll call it Model N. (I’m leaving myself room for more models in the middle.)
 !/images/2004/serving-clients/webapp-dataflow-legend-4.png!
!/images/2004/serving-clients/webapp-dataflow-legend-4.png!
One thing to note about Model N is that the client side is radically different from Models 1-4. Instead of a sequence of pages that replace each other, the application is delivered as a single HTML page that embeds an application. This application in turn consumes a series of datasets.
The other thing to note about Model N is that the server side is very similar to Model 2, or MVC — in fact, much more similar than the failed Model 4 is. Just like in Model 2, the server is implemented as a set of JSPs. The major difference is that instead of rendering HTML, most of these JSPs are rendering XML — or, serializing data to XML. (In many applications, this may mean that some JSPs can be eliminated. A JSP isn’t necessary if it was only transforming a datasource that is already in XML into HTML.)
And last, a caveat: it’s possible to take this too far. I’ve only illustrated the part of a web application that can be replaced by a client-side application. It doesn’t generally make sense to do this with an entire web site. HTML is still best-of-breed for delivering hyperlinked, structured documents, and most parts of a web site are more like documents than like applications. The part of the Model N data flow that I haven’t drawn is at the end of the application, when the server transitions back into a series of HTML-generating JSPs, and the client transitions back into a series of HTML pages.
Notes
-
“a lot of embedded JavaScript”: “A lot” meaning on the order of Oddpost or GMail, say, as opposed to just rollover effects and form validation. ↩
-
“a little bulky”: Model 4 replaces Model 2 and Model 3’s single level of code generation with two: one from JSP to Laszlo source file, and from Laszlo source file to executable. ↩
-
“each interaction”: Aside from local view manipulations such as rollovers and scrolling, and aside from pre-submission form editing. ↩
-
“without delivering any additional benefit to the user”: In a client-side application that is also a rich application, you can compile some cool effects such as dynamic layout and declarative animation into each page of your application, but there’s no benefit at the user task level. ↩